Stalled uWSGI Workers
Problem: We had some web hosts that were returning requests slower
The problem was intermittent, and our monitoring data didn’t show any specific thing that had slowed down. Sometimes the hosts would begin failing health checks, and in the worst case, some requests would time out.
As I continued the investigation, I began sharing what I had found in Slack, on our SRE channel and Web developer channel. I looked for recent changes that might be causing trouble, but nothing stood out. I noticed that some of the health check failures aligned with some increased request rate, so began looking for evidence of resource exhaustion.
In previous cases, I had seen uWSGI run out of spare workers and start growing the listen queue. To troubleshoot this kind of issue, we had the uWSGI stats server enabled, and can use uwsgitop. Instead of seeing all workers busy serving requests, I saw something different. On this server, worker 1 was serving all requests while the others served no requests.
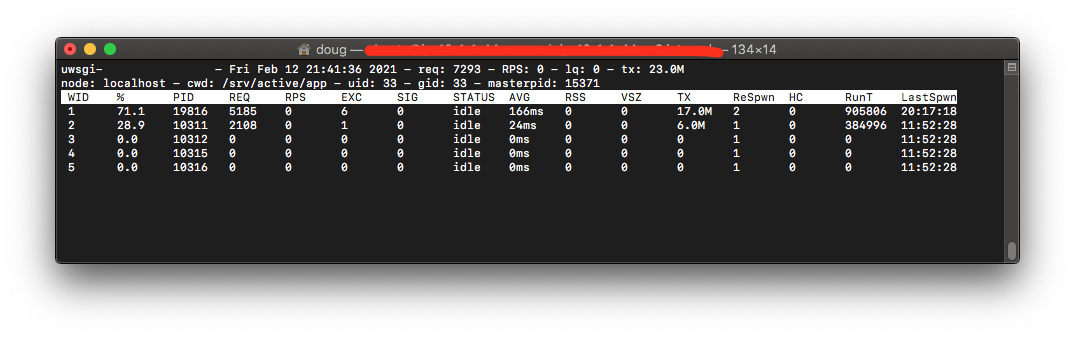
It’s quite common for the uwsgi workers to serve an unequal number of requests, but one or two workers serving all requests was not normal. To be sure, I used ab to send a larger number of concurrent requests, and they were still served by worker 1 while the others remained idle, and the listen queue grew.
We also have the python tracebacker feature enabled on uWSGI. When enabled, and a request is killed by the harikiri timeout, a python traceback is printed to the log. However, a socket is also available to request a traceback on demand. This feature is useful when troubleshooting requests that take too long and use up all available workers.
In this case, I wanted to see why these workers were not serving any requests. However, the traceback socket for workers that had served no requests would not accept connections. These workers appear to have some startup issue, and never reach a working state.
$ sudo uwsgi --connect-and-read /tmp/tbsocket3
uwsgi_connect(): Connection refused [core/uwsgi.c line 4529]
Cause: uWSGI workers were in a non-functioning state
I’ve seen similar issues before, with some of our celery workers. In previous cases, it was a python library with c bindings that were not fork-safe. With the new focus, I again shared my findings with the broader team, and checked for recent changes that could cause this issue. However, I didn’t find a specific change.
I began looking for bug reports and discussions of other similar issues. I found some discussions that suggest libraries that use multithreading at the time of the worker prefork can cause issues, and sometimes the python standard library logging can cause these issues.
I realized that I can’t be sure it was one specific change, or be sure of when exactly the problem was introduced. Meanwhile, I have a degraded service. While it would be nice to solve it the right way, by working with the development team to identify the root cause and rework the startup of our application to ensure it survives the fork, we may not be able to do that quickly.
Solution: Use uWSGI lazy-apps
uWSGI has a large number of settings, some of them are even well documented. Lazy-apps is easy to understand though. Without lazy-apps, the application is loaded, and then forked to create the worker processes. With lazy-apps, the workers fork, and then load the application. If the issue is with multithreading at the time of a fork, then enabling this setting will avoid the issue.
Lazy-apps does have some disadvantages. Startup time can increase, since each worker must init the application at the same time, rather than just once. Base memory usage can increase, since it is no longer loaded by the parent before forking.
Before doing a full rollout, we did want to confirm that it would work. I identified a metric in prometheus to watch, the number of requests served by each worker on each server. This is the same metric I identified in uwsgitop earlier. We could look for workers that have served 0 requests. We assigned a portion of our servers to use lazy-apps, and we would monitor the state of those servers vs the others that had the old config.
This issue generally appears after a restart, so most often this would occur after a deployment. After a couple deployments, it appears that servers with lazy-apps no longer experience this issue.