Dynamic Joy with Clojure and the Twitter API
The Twitter API has been a source of joy for many data scientists ever since its inception. Open by design, of impressive volume, dynamic and ever-changing, Twitter data can be used in countless ways to deepen our understanding of natural languages. At Shareablee we use V1, V2 and some paid Twitter endpoints.
In the real world, we use pretty sophisticated techniques to create NLP products from Twitter data. But here we propose a very simple exploration, without any NLP tools at our disposal. We will try to answer the question: people who are, at this very moment, talking about a specific trend, what are they saying about it, what terms are they employing when mentioning it? And since we have been talking about things that are dynamic and a source of joy, why don’t we use Clojure for this small exploration?
Let us start by making a call to the Twitter API to get the latest tweets that mention Clojure:
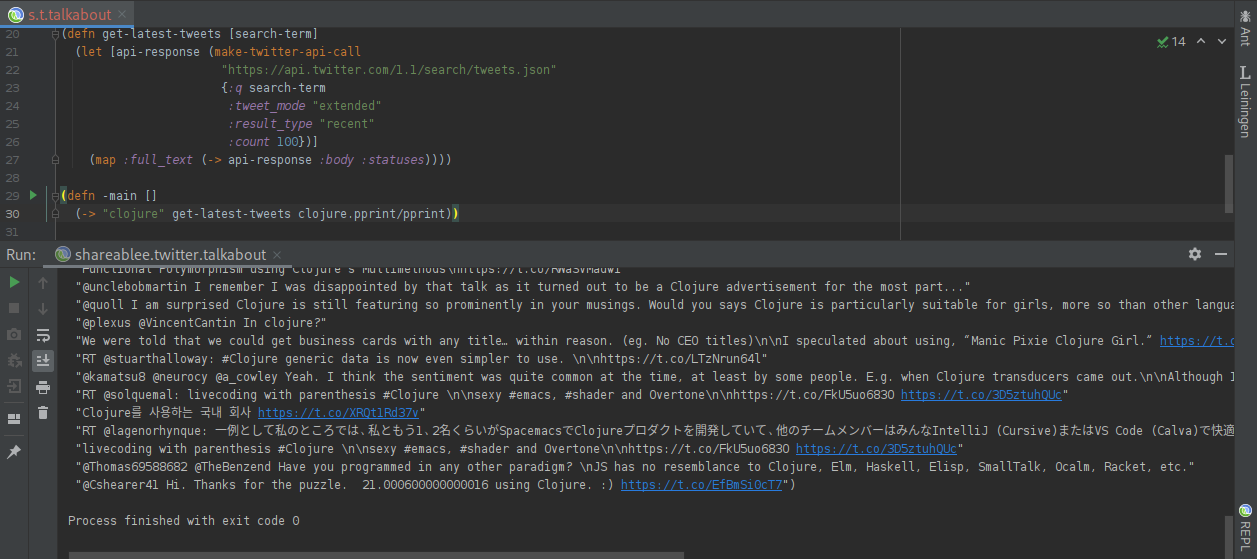
The parameters we need to set are documented at:
https://developer.twitter.com/en/docs/twitter-api/v1/tweets/search/api-reference/get-search-tweets
We cannot get more than 100 tweets with a single call – but that will be sufficient for our very simple experiment.
Our next step is going to be to implement the world’s most naive tokenizer. It simply splits the tweet into words by cutting at any character that is not a letter. Obviously, this is a very bad tokenizer, not recommended for production use! The Lucene library, for example, contains a number of much better ones. But for our experiment, this naive tokenizer might just be good enough:
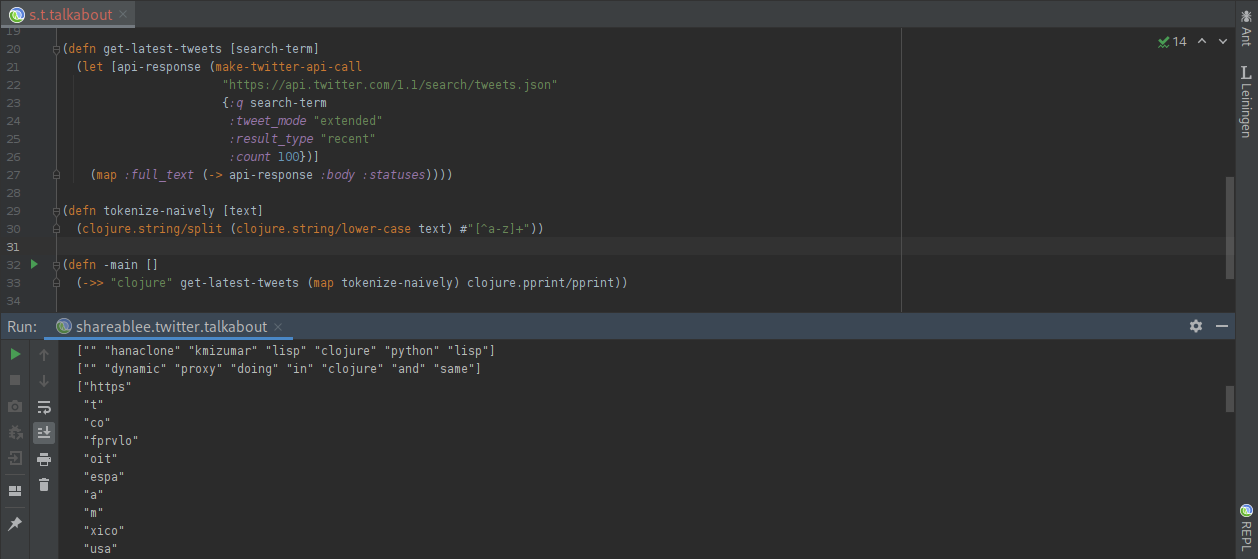
Great, now we have split the tweets into words. The next step is to remove the duplicate words within each tweet, by turning each tweet into a set of terms:
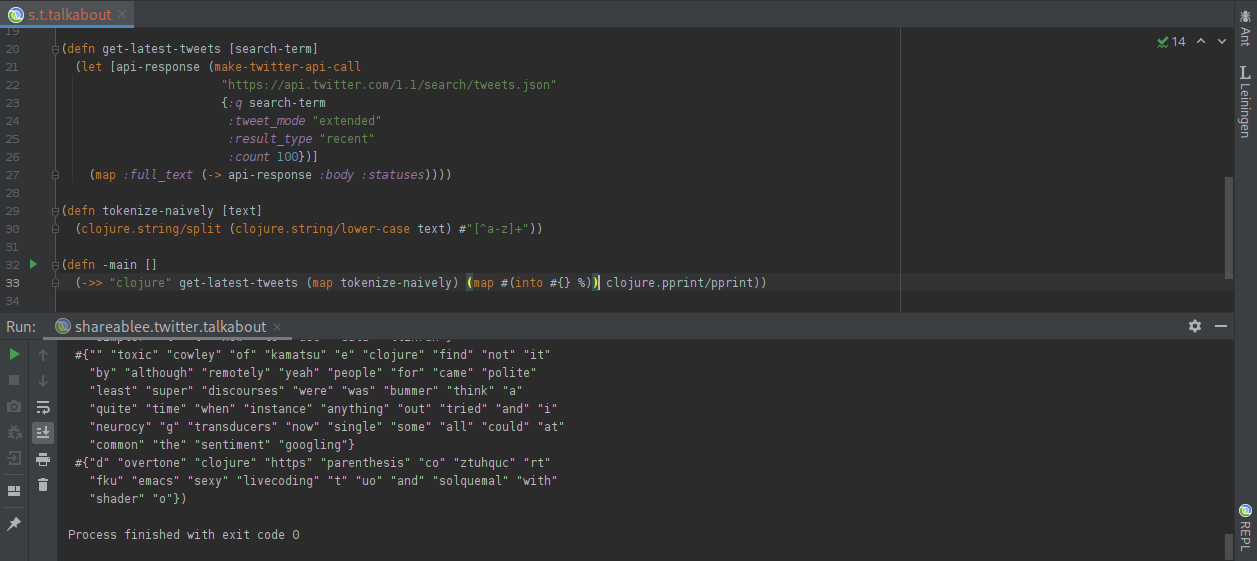
Wonderful! Now we can turn the sets back into lists, and then use “flatten” to merge them all together into one giant list of tokens:
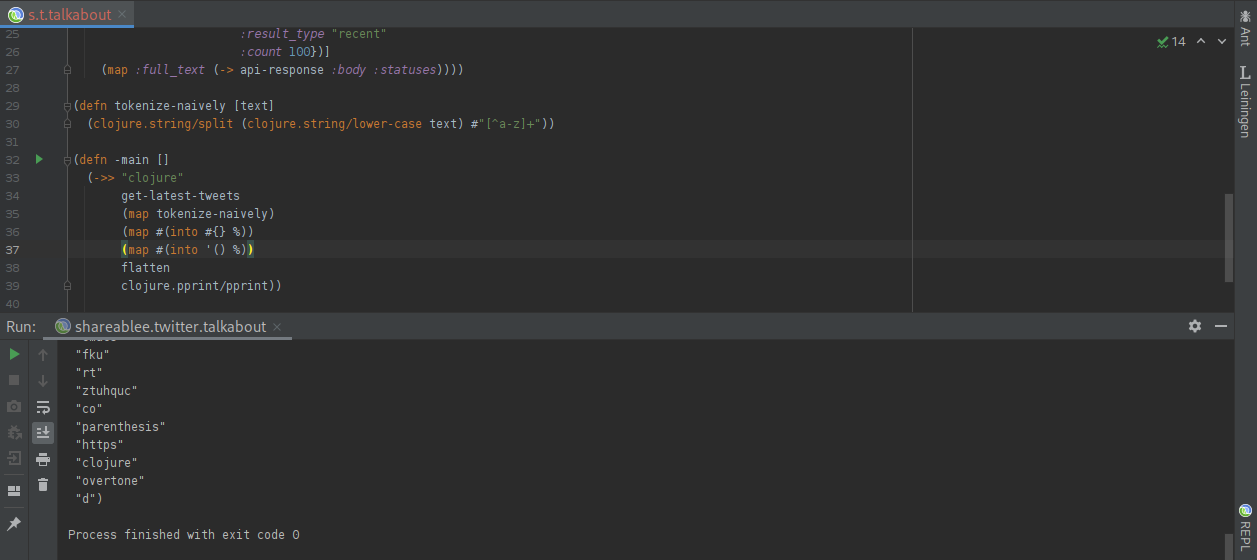
In the next step, we utilize the wonderful function “frequencies” which simply tells us how many times each word is present in the combined list. In addition, we sort those frequencies by value, so that we can easily see the most popular terms:
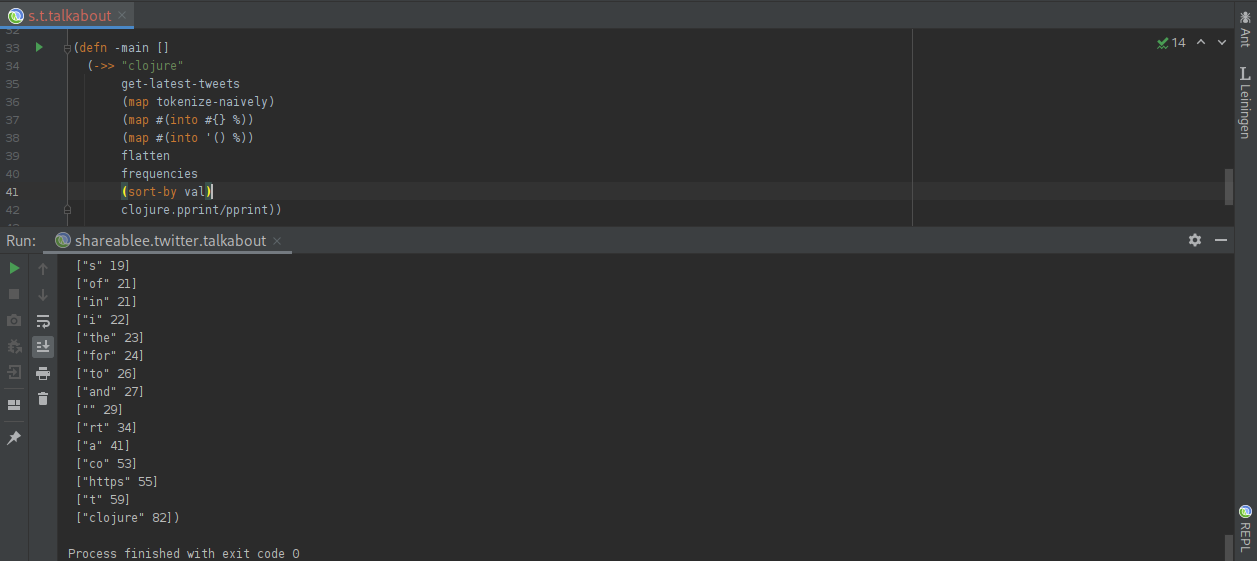
Here we see some good news and some bad news. The good news: the term Clojure is the clear leader here, which is what we expected! The bad news: we forgot to remove the uninteresting, or common words, also known as stop words!
We are going to use a stop words remover that is as naive (and bad) as our tokenizer. We are simply going to say that every word of 3 or fewer characters is a stop word. That is, of course, incorrect! But may be good enough for us here:
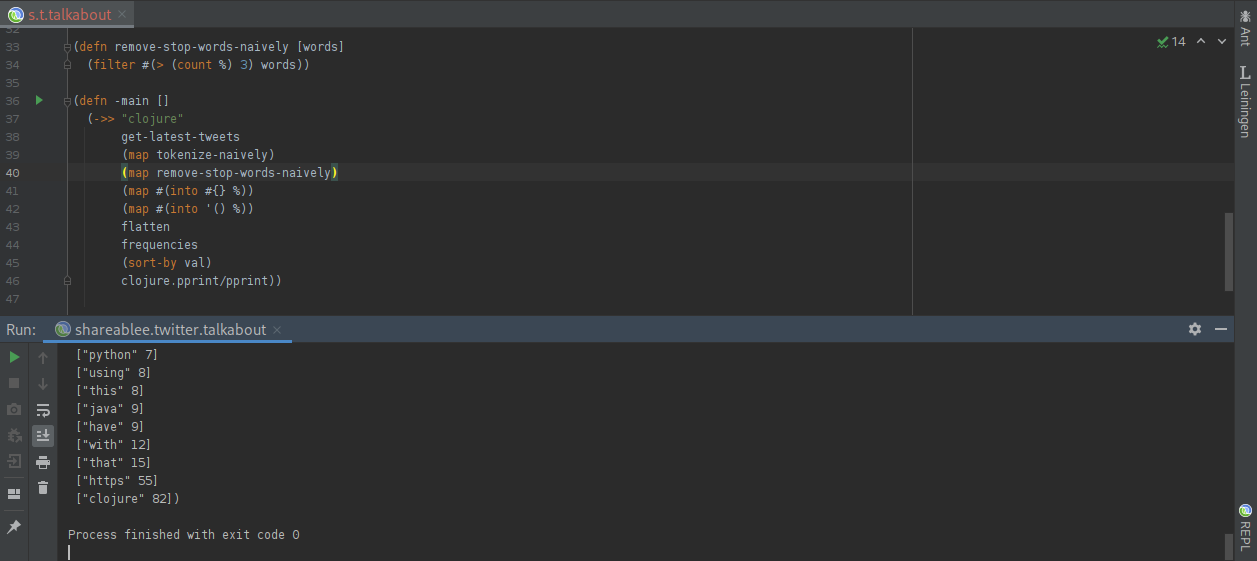
We still have some stop words left, such as “with” and “that”, but things look cleaner. And we can see that when people talk about Clojure at this moment, the two things they mention the most are Java and Python. That is not entirely surprising!
Let us use this little tool to perform another small experiment. If we replace Clojure with Smith, will it give us the Smiths that people are talking about at this moment?
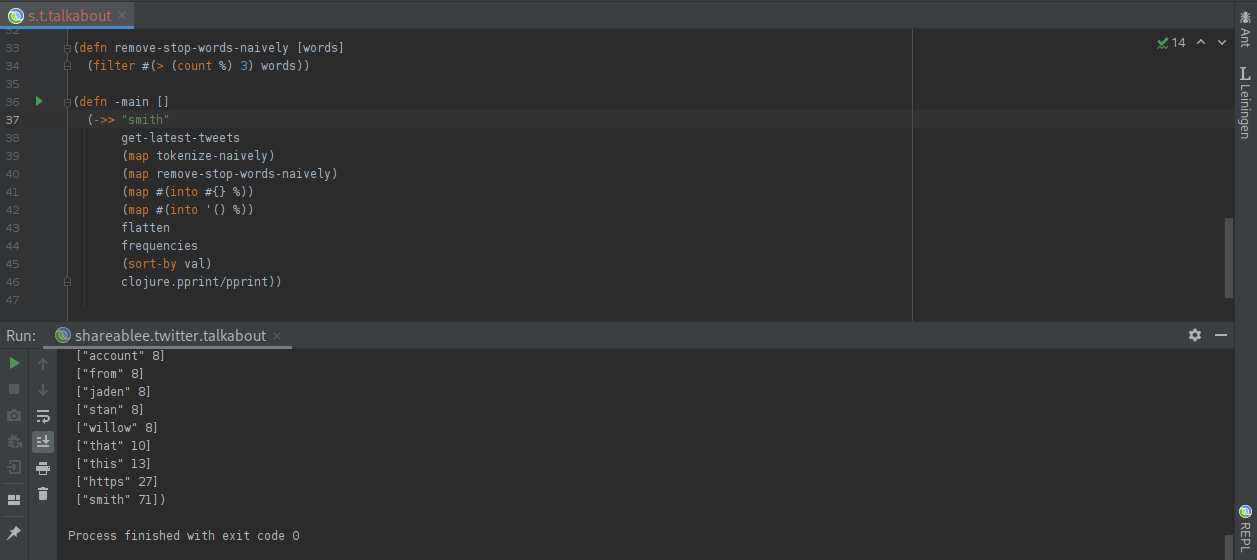
It looks like Willow Smith, Stan Smith and Jaden Smith are the Smiths that are all the rage right now. I am not in touch with the latest developments in pop culture, so I had to google all three of them. You can imagine my surprise to find out that one of them is not a human, but a brand of shoes! In any case, it looks like our very simple tool was able to provide a reasonable answer to our question.
The code that we ended up with:
(defn get-latest-tweets [search-term]
(let [api-response (make-twitter-api-call
"https://api.twitter.com/1.1/search/tweets.json"
{:q search-term
:tweet_mode "extended"
:result_type "recent"
:count 100})]
(map :full_text (-> api-response :body :statuses))))
(defn tokenize-naively [text]
(clojure.string/split (clojure.string/lower-case text) #"[^a-z]+"))
(defn remove-stop-words-naively [words]
(filter #(> (count %) 3) words))
(defn -main []
(->> "smith"
get-latest-tweets
(map tokenize-naively)
(map remove-stop-words-naively)
(map #(into #{} %))
(map #(into '() %))
flatten
frequencies
(sort-by val)
clojure.pprint/pprint))